從一個浪潮案例看海量數據的分級保護應用
導讀:移動互聯時代,企業都面臨著海量數據帶來的挑戰,有一些企業馴服了海量數據,實現了“存的下、算的出”,但即使如此,這些企業很少跨過數據保護的門檻,因為傳統數據保護技術在面對PB級別數據量時,都或多或少的出現了問題,浪潮工程師開發了分級保護方案,很好的滿足了100PB級別的數據保護需求。
PB數據量挑戰傳統數據保護技術
提到數據保護和容災,很多人都會想到備份技術、存儲復制技術、數據卷復制技術、數據庫日志傳輸等,但是這些傳統技術沒法適應海量數據環境。數PB乃至數十PB規模的數據,是傳統數據保護技術和容災技術在設計和形成之初,所不能想象的。這些技術適用于百TB以下數據規模,大多數不能做到實時保護,容災數據日常處于離線或不可訪問狀態,難以滿足大數據的應用需求。
勉強部署這些技術在海量數據環境下,災難恢復、可用性、穩定性等技術表現也會大打折扣。拿傳統備份技術來說,日常演練/驗證,數據需要重新加載,PB級數據環境下,加載時間往往是數天、甚至數周,若容災數據不能進行有效的日常驗證,整個容災架構的可靠性和實用性會急劇下降,所以在很多場景中,傳統方案僅限于方案,不能實際部署。
數據分級解決大數據容災問題
OpenStack、Hadoop、Spark等目前主流的云和大數據平臺,數據可靠性主要通過存儲子系統的副本和糾刪碼等技術來保證,這些技術只能保證本地數據安全可靠,沒法應對人為破壞、物理/邏輯故障、站點故障等情況,需要增加歷史數據保護和遠距離容災保護。
大數據平臺80%左右都是原始數據,這些數據經過數據清洗、治理形成平臺的標準資源庫數據,這個環節是一個海量數據結構化的過程,隨后,根據上層業務應用需求,由標準資源庫快速派生出多個主題庫、專題庫等,這些數據庫就直接對接上層應用了。
海量數據保護需要在深入了解業務模型和數據屬性的技術上,對這些數據進行分級保護,根據重要程度等技術指標,執行不同的保護策略,避免了成本高、技術難落地等實際問題。
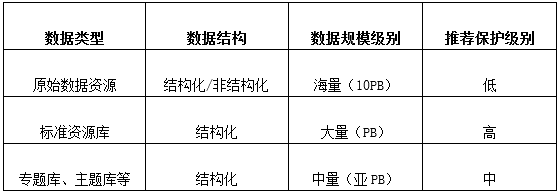
數據分級保護
一個案例——50PB數據的保護
分級僅是海量數據保護的方案框架,具體方案需要針對客戶的具體應用場景進行設計,所以我們以剛剛成功上線的一個案例來詳細展開。
該用戶的數據量屬于超大規模級別,在全省有11個大數據分中心,1個大數據總中心,各個中心采集自己區域的原始數據,生成本地的標準資源庫,然后根據各自需求生成本地的主題庫、專題庫等,承接本地上層的應用;同時,各分中心傳輸本地的標準資源庫至總中心,匯聚為全省的標準資源庫,生成相關主題庫、專題庫,具備承接全省范圍內業務需求的能力,12個中心數據總量接近50PB。
數據分析——50PB數據保護1PB即可
用戶希望建立有效的容災機制,防范物理、邏輯、站點等故障。根據上文所述的原則,需要先對客戶的數據進行分類,根據不同的重要程度采取不同的數據保護技術。
首先是原始數據,這些數據可再生,而且據經過熱度訪問期后,便成為冷數據,價值低,規模大,不必采用額外的保護技術;其次是,標準資源庫數據,這些庫數據是大數據平臺的初次結果數據,含金量很高,是用戶大數據環境的核心數據,不易重建,有很強的數據保護和容災需求,然后是各類主題庫、專題庫等數據,這些庫數據由標準資源庫數據經過二次加工派生出而出,并支持快速重建,發生問題可以在用戶要求的RTO(復原時間目標)內完成重建,因而這類數據也不需要額外容災保護。最后則是各中心間冗余數據,顯然這些數據不需要容災保護
綜上,本項目僅需要為總中心的全量標準資源庫數據進行容災保護,數據量約1PB。
應用方案——3條傳輸通路冗余、計算存儲分離
浪潮為用戶設計了異地容災方案,將方案按照客戶要求部署在分數據中心10中。總中心的全量標準資源庫有1PB結構化數據,每日數據變化量為30TB~50TB,所以,異地容災架構中數據傳輸技術要支持高頻率周期性傳輸和實時傳輸模式,將增量數據復制過來,根據生產環境的壓力變化兩種傳輸技術可以靈活組合,保證異地容災大數據平臺為在線狀態,日常可以實時查詢數據、驗證數據。所以,容災數據傳輸采用ETL定制化工具,這種數據傳輸技術與大數據平臺有著天然的親和性,高速穩定、成熟可靠,目前,容災方案可以保證RPO≤1小時,RTO≤2小時。
最后,容災中心大數據平臺,采用計算和存儲分離的部署模式,容災存儲采用企業級分布式存儲,并和上層大數據平臺對接,使方案具備很強的數據湖特性:容災數據可以靈活的分配給非大數據平臺環境,支持容災數據在不同類型的業務系統間共享,避免數據再次復制過程,最大化數據價值。
以下為容災方案技術架構圖:
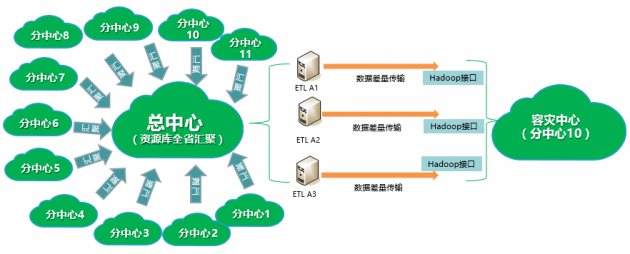
容災方案技術架構圖
本項目在總中心部署3臺ETL服務器(后續計劃在容災中心也部署3臺,實現ETL服務器的站點互備架構),形成三條邏輯冗余的數據傳輸通道,從總中心大數據平臺抽取標準資源庫全量數據至容災中心,之后進行差量數據復制,容災中心數據和生產中心數據保持一定的時間差異,可以提升防范邏輯數據故障的能力。
容災中心,日常主要工作為接收總中心標準資源庫數據,并提供數據查詢、驗證服務、低頻運行臨時分配的作業任務,根據建設目標,此平臺配置和生產中心標準資源庫同量存儲資源,但不需配置同等的計算資源,所以,本方案采用30臺服務器(約為總中心大數據平臺計算力的10%)、40臺高密存儲節點(配置海量數據存儲池,提供4PB可用容量,實現未來三年的容量預留)搭建大數據容災平臺。30臺服務器包括1臺管理節點、2臺主服務節點以及27臺數據節點,平臺服務組件采用高可靠主備模式,防止單節點故障問題。海量存儲池采用糾刪數據冗余機制,保證可靠性和空間利用率,海量存儲池,被上層大數據平臺管理,隨著容災數據的快速增長,可以實現在不擴容平臺計算資源的條件下,在線擴展其容量至數百PB,滿足用戶后期數據的快速增長需求。
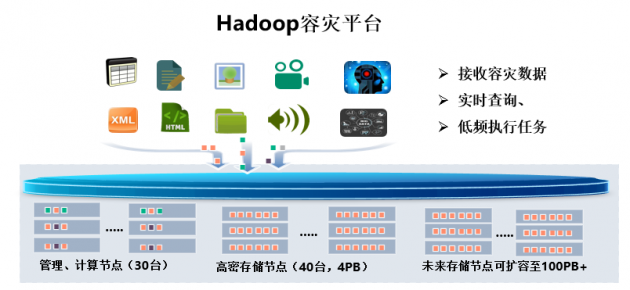
Hadoop容災平臺
結語,海量數據將是企業新常態
目前全球數據量約為44ZB,到2025年會上升至163ZB,也就是說,數據的高速增長將成為越來越多的企業面臨的常態化問題,而不是新挑戰。在可見的時間內,網絡等方面的技術條件都不足以使得企業進行全面不加取舍的數據保護,分級保護將成為越來越多用戶的選擇,希望這個案例能夠給更多的企業用戶提供良好的借鑒范例。
- 標簽:
- 編輯:馬可
- 相關文章

